The concepts and architectures of a data warehouse, a data lake, and data streaming are complementary to solving business problems. Storing data at rest for reporting and analytics requires different capabilities and SLAs than continuously processing data in motion for real-time workloads. Many open-source frameworks, commercial products, and SaaS cloud services exist. Unfortunately, the underlying technologies are often misunderstood, overused for monolithic and inflexible architectures, and pitched for wrong use cases by vendors. Let’s explore this dilemma in a blog series. Learn how to build a modern data stack with cloud-native technologies. This is part 2: Data Streaming for Data Ingestion into the Data Warehouse and Data Lake.
Blog Series: Data Warehouse vs. Data Lake vs. Data Streaming
This blog series explores concepts, features, and trade-offs of a modern data stack using a data warehouse, data lake, and data streaming together:
- Data Warehouse vs. Data Lake vs. Data Streaming – Friends, Enemies, Frenemies?
- THIS POST: Data Streaming for Data Ingestion into the Data Warehouse and Data Lake
- Data Warehouse Modernization: From Legacy On-Premise to Cloud-Native Infrastructure
- Case Studies: Cloud-native Data Streaming for Data Warehouse Modernization
- Lessons Learned from Building a Cloud-Native Data Warehouse
Stay tuned for a dedicated blog post for each topic as part of this blog series. I will link the blogs here as soon as they are available (in the next few weeks). Subscribe to my newsletter to get an email after each publication (no spam or ads).
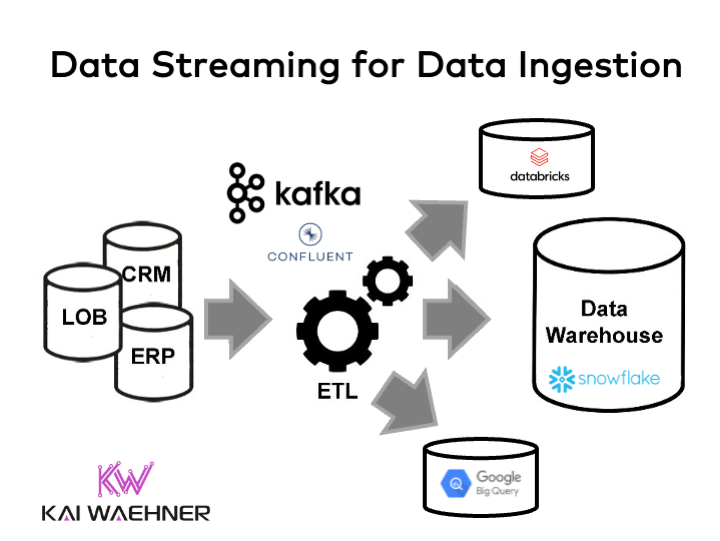
Reliable and scalable data ingestion with data streaming
Reliable and scalable data ingestion is crucial for any analytics platform, whether you build a data warehouse, data lake, or lakehouse.
Almost every major player in the analytics space re-engineered the existing platform to enable data ingestion in (near) real-time instead of just batch integration.
Data ingestion = data integration
Just getting data from A to B is usually not enough. Data integration with Extract, Transform, Load (ETL) workflows connects to various source systems and processes incoming events before ingesting them into one or more data sinks. However, most people think about a message queue when discussing data ingestion. Instead, a good data ingestion technology provides additional capabilities:
- Connectivity: Connectors enable a quick but reliable integration with any data source and data sink. Don’t build your own connector if a connector is available!
- Data processing: Integration logic filters, enriches, or aggregates data from one or more data sources.
- Data sharing: Replicate data across regions, data centers, and multi-cloud.
- Cost-efficient storage: Truly decouple data sources from various downstream consumers (analytics platforms, business applications, SaaS, etc.)
Kafka is more than just data ingestion or a message queue. Kafka is a cloud-native middleware:
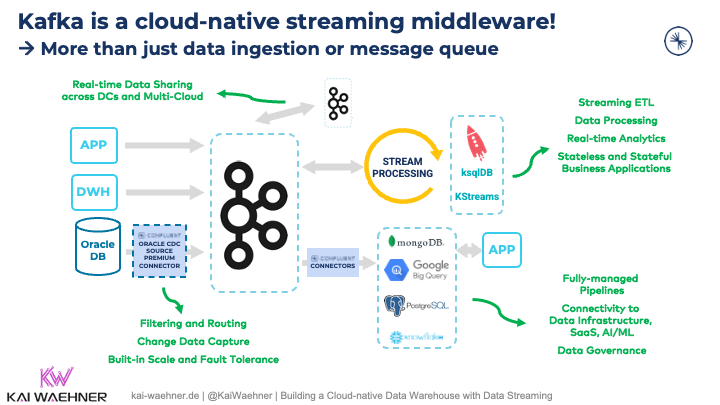
One common option is to run ETL workloads in the data warehouse or data lake. A message queue is sufficient for data ingestion. Even in that case, most projects use the data streaming platform Apache Kafka as the data ingestion layer, even though many great Kafka features are disregarded this way.
Instead, running ETL workloads in the data ingestion pipeline has several advantages:
- True decoupling between the processing and storage layer enables a scalable and cost-efficient infrastructure.
- ETL workloads are processed in real-time, no matter what pace each downstream application provides.
- Each consumer (data warehouse, data lake, NoSQL database, message queue) has the freedom of choice for the technology/API/programming language/communication paradigm to decide how and when to read, process, and store data.
- Downstream consumers choose between raw data and curated relevant data sets.
Data integration at rest or in motion?
ETL is nothing new. Tools from Informatica, TIBCO, and other vendors provide great visual coding for building data pipelines. The evolution in the cloud brought us cloud-native alternatives like SnapLogic or Boomi. API Management tools like MuleSoft are another common option for building an integration layer based on APIs and point-to-point integration.
The enormous benefit of these tools is a much better time-to-market for building and maintaining pipelines. A few drawbacks exist, though:
- Separate infrastructure to operate and pay for
- Often limited scalability and/or latency using a dedicated middleware compared to a native stream ingestion layer (like Kafka or Kinesis)
- Data stored at rest in separate storage systems
- Tight coupling with web services and point-to-point connections
- Integration logic lies in the middleware platform; expertise and proprietary tooling without freedom of choice for implementing data integration
The great news is that you have the freedom of choice. If the heart of the infrastructure is real-time and scalable, then you can add not just scalable real-time applications but any batch or API-based middleware:
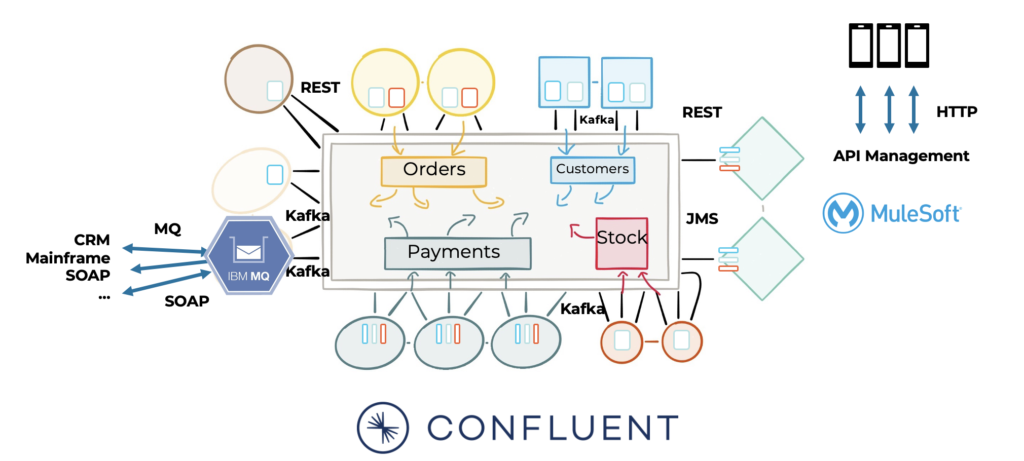
Point-to-point integration via API Management is complementary to data streaming, not competitive.
Data mesh for multi-cloud data ingestion
Data Mesh is the latest buzzword in the software industry. It combines domain-driven design, data marts, microservices, data streaming, and other concepts. Like Lakehouse, Data Mesh is a logical concept, NOT physical infrastructure built with a single technology! I explored what role data streaming with Apache Kafka plays in a data mesh architecture.
In summary, the characteristics of Kafka, such as true decoupling, backpressure handling, data processing, and connectivity to real-time and non-real-time systems, enable the building of a distributed global data architecture.
Here is an example of a data mesh built with Confluent Cloud and Databricks across cloud providers and regions:
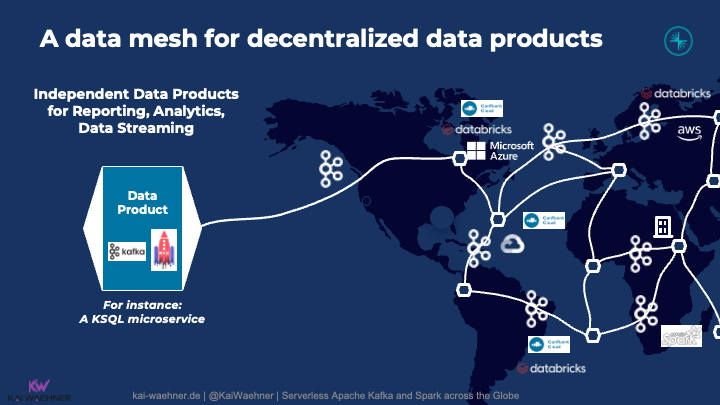
Data streaming as the data ingestion layer plays many roles in a multi-cloud and/or multi-region environment:
- Data replication between clouds and/or regions
- Data integration with various source applications (either directly or via 3rd party ETL/iPaaS middleware)
- Preprocessing in the local region to reduce data transfer costs and improve latency between regions
- Data ingestion into one or more data warehouses and/or data lakes
- Backpressure handling for slow consumers or between regions in case of disconnected internet
The power of data streaming becomes more apparent in this example: Data ingestion or a message queue alone is NOT good enough for most “data ingestion projects“!
Apache Kafka – The de facto standard for data ingestion into the lakehouse
Apache Kafka is the de facto standard for data streaming, and a critical use case is data ingestion. Kafka Connect enables a reliable integration in real-time at any scale. It automatically handles failure, network issues, downtime, and other operations issues. Search for your favorite analytics platform and check the availability of a Kafka Connect connector. The chances are high that you will find one.
Critical advantages of Apache Kafka compared to other data ingestion engines like AWS Kinesis include:
- True decoupling: Data ingestion into a data warehouse is usually only one of the data sinks. Most enterprises ingest data into various systems and build new real-time applications with the same Kafka infrastructure and APIs.
- Open API across multi-cloud and hybrid environments: Kafka can be deployed everywhere, including any cloud provider, data center, or edge infrastructure.
- Cost-efficiency: The more you scale, the more cost-efficient Kafka workloads become compared to Kinesis and similar tools.
- Long-term storage in the streaming platform: Replayability of historical data and backpressure handling for slow consumers are built into Kafka (and cost-efficient if you leverage Tiered Storage).
- Pre-processing and ETL in a single infrastructure: Instead of ingesting vast volumes of raw data into various systems at rest, the incoming data can be processed in motion with tools like Kafka Streams or ksqlDB once. Each consumer chooses the curated or raw data it needs for further analytics – in real-time, near real-time batch, or request-response.
Kafka as data ingestion and ETL middleware with Kafka Connect and ksqlDB
Kafka provides two capabilities that many people often underestimate in the beginning (because they think about Kafka just as a message queue):
- Data integration: Kafka Connect is a tool for scalably and reliably streaming data between Apache Kafka and other data systems. Kafka Connect makes it simple to quickly define connectors that move large data sets into and out of Kafka.
- Stream Processing: Kafka Streams is a client library for building stateless or stateful applications and microservices, where the input and output data are stored in Kafka clusters. ksqlDB is built on top of Kafka Streams to build data streaming applications leveraging your familiarity with relational databases and SQL.
The key difference from other ETL tools is that Kafka eats its own dog food:
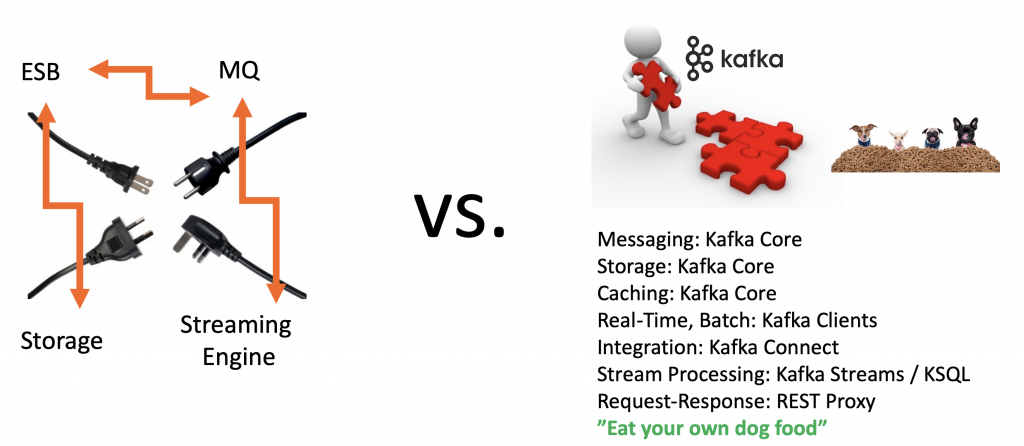
Please note that Kafka Connect is more than a set of connectors. The underlying framework provides many additional middleware features. Look at single message transforms (SMT), dead letter queue, schema validation, and other capabilities of Kafka Connect.
Kafka as cloud-native middleware; NOT iPaaS
Data streaming with Kafka often replaces ETL tools and ESBs. Here are the key reasons:
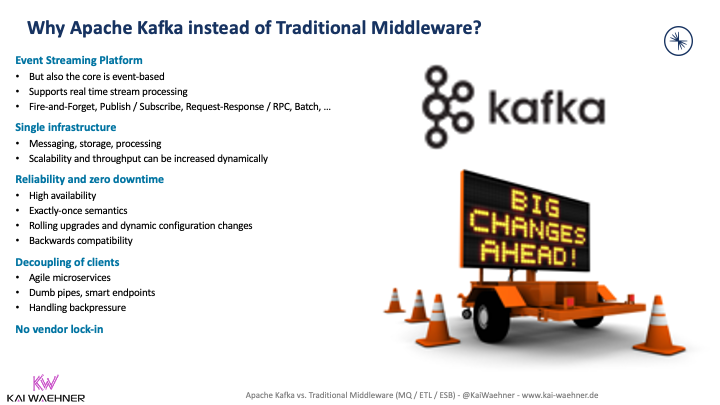
Some consider data streaming an integration platform as a service (iPaaS). I can’t entirely agree with that. The arguments are very similar to saying Kafka is an ETL tool. These are very different technologies that shine with other characteristics (and trade-offs). Check out my blog post explaining why data streaming is a new software category and why Kafka is NOT an iPaaS.
Reference architectures for data ingestion with Apache Kafka
Let’s explore two example architectures for data ingestion with Apache Kafka and Kafka Connect: Elasticsearch Data Streams and Databricks Delta Lake. Both products serve very different use cases and require a different data ingestion strategy.
The developer can use the same Kafka Connect APIs for different connectors. Under the hood, the implementation looks very different to serve different needs and SLAs.
Both are using the dedicated Kafka Connect connector on the high-level architecture diagram. Under the hood, ingestion speed, indexing strategy, delivery guarantees, and many other factors must be configured depending on the project requirements and data sink capabilities.
Data ingestion example: Real-time indexing with Kafka and Elasticsearch Data Streams
One of my favorite examples is Elasticsearch. Naturally, the search engine built indices in batch mode. Hence, the first Kafka Connect connector ingested events in batch mode. However, Elastic created a new real-time indexing strategy called Elasticsearch Data Streams to offer its end users faster query and response times.
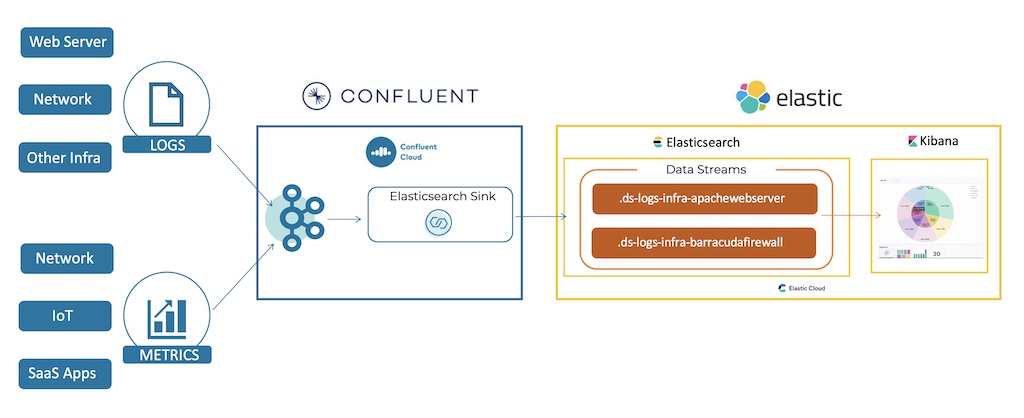
An Elastic Data Stream lets you store append-only time series data across multiple indices while giving you a single named resource for requests. Data streams are well-suited for logs, events, metrics, and other continuously generated data. You can submit indexing and search requests directly to a data stream. The stream automatically routes the request to backing indices that store the stream’s data. A Kafka data stream is the ideal data source for Elastic Data Streams.
Data ingestion example: Confluent and Databricks
Confluent in conjunction with Databricks is another excellent example. Many people struggle to explain both vendors’ differences and unique selling points. Why? Because the marketing looks very similar for both: Process big data, store it forever, analyze it in real-time, deploy across multi-cloud and multi-region, and so on. The reality is that Confluent and Databricks overlap only ~10%. Both complement each other very well.
Confluent’s focus is to process data in motion. Databricks’ primary business is storing data at rest for analytics and reporting. Yes, you can store data long term in Kafka (especially with Tiered Storage). Yes, you can process data with Databricks in (near) real-time with Spark Streaming. That’s fine for some use cases, but in most scenarios, you (should) choose and combine the best technology for a problem.
Here is a reference architecture for data streaming and analytics with Confluent and Databricks:
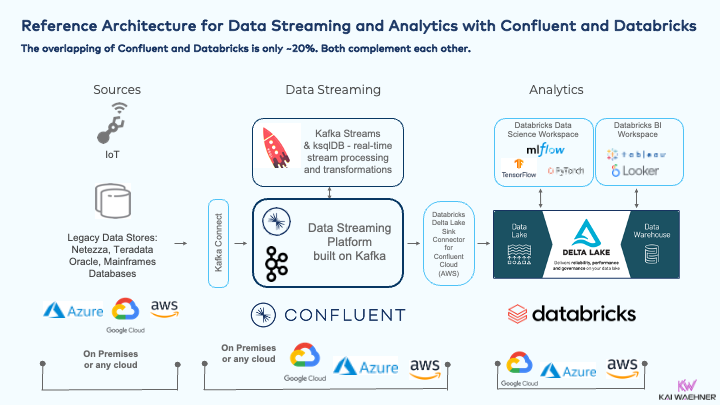
Confluent and Databricks are a perfect combination of a modern machine learning architecture:
- Data ingestion with data streaming
- Model training in the data lake
- (streaming or batch) ETL where it fits the use case best
- Model deployment in the data lake close to the data science environment or a data streaming app for mission-critical SLAs and low latency
- Monitoring the end-to-end pipeline (ETL, model scoring, etc.) in real-time with data streaming
I hope it is clear that data streaming vendors like Confluent have very different capabilities, strengths, and weaknesses than data warehouse vendors like Databricks or Snowflake.
How to build a cloud-native lakehouse with Kafka and Spark?
Databricks coined Lakehouse to talk about real-time data in motion and batch workloads at rest in a single platform. From my point of view, the Lakehouse is a great logical view. But there is no silver bullet! The technical implementation of a Lakehouse requires different tools in a modern data stack.
In June 2022, I presented my detailed perspective on this discussion at Databricks’ Data + AI Summit in San Francisco. Check out my slide deck “Serverless Kafka and Spark in a Multi-Cloud Lakehouse Architecture“:
You are currently viewing a placeholder content from Default. To access the actual content, click the button below. Please note that doing so will share data with third-party providers.
Data streaming is much more than data ingestion into a lakehouse
Data streaming technologies like Apache Kafka are perfect for data ingestion into one or more data warehouses and/or data lakes. BUT data streaming is much more: Integration with various data sources, data processing, replication across regions or clouds, and finally, data ingestion into the data sinks.
Examples with vendors like Confluent, Databricks, and Elasticsearch showed how data streaming helps solve many data integration challenges with a single technology.
Nevertheless, there is no silver bullet. A modern lakehouse leverages a best of breed technologies. No single technology can be the best to handle all kinds of data sets and communication paradigms (like real-time, batch, request-response).
For more details, browse other posts of this blog series:
- Data Warehouse vs. Data Lake vs. Data Streaming – Friends, Enemies, Frenemies?
- THIS POST: Data Streaming for Data Ingestion into the Data Warehouse and Data Lake
- Data Warehouse Modernization: From Legacy On-Premise to Cloud-Native Infrastructure
- Case Studies: Cloud-native Data Streaming for Data Warehouse Modernization
- Lessons Learned from Building a Cloud-Native Data Warehouse
How do you combine data warehouse and data streaming today? Is Kafka just your ingestion layer into the data lake? Do you already leverage data streaming for additional real-time use cases? Or is Kafka already the strategic component in the enterprise architecture for decoupled microservices and a data mesh? Let’s connect on LinkedIn and discuss it! Stay informed about new blog posts by subscribing to my newsletter.